
# 6: Life Science x AI

Welcome back to your weekly dose of AI news for Life Science!
Here’s what we have for you this week:
EHR data for AI 💿
New language model for therapeutics 💊
Life Science tools of the week 🛠️
We have started working on an AI Scientist to design, execute and troubleshoot scientific experiments …. join the waiting list to be the first one to try it!
EHR data for AI 💿
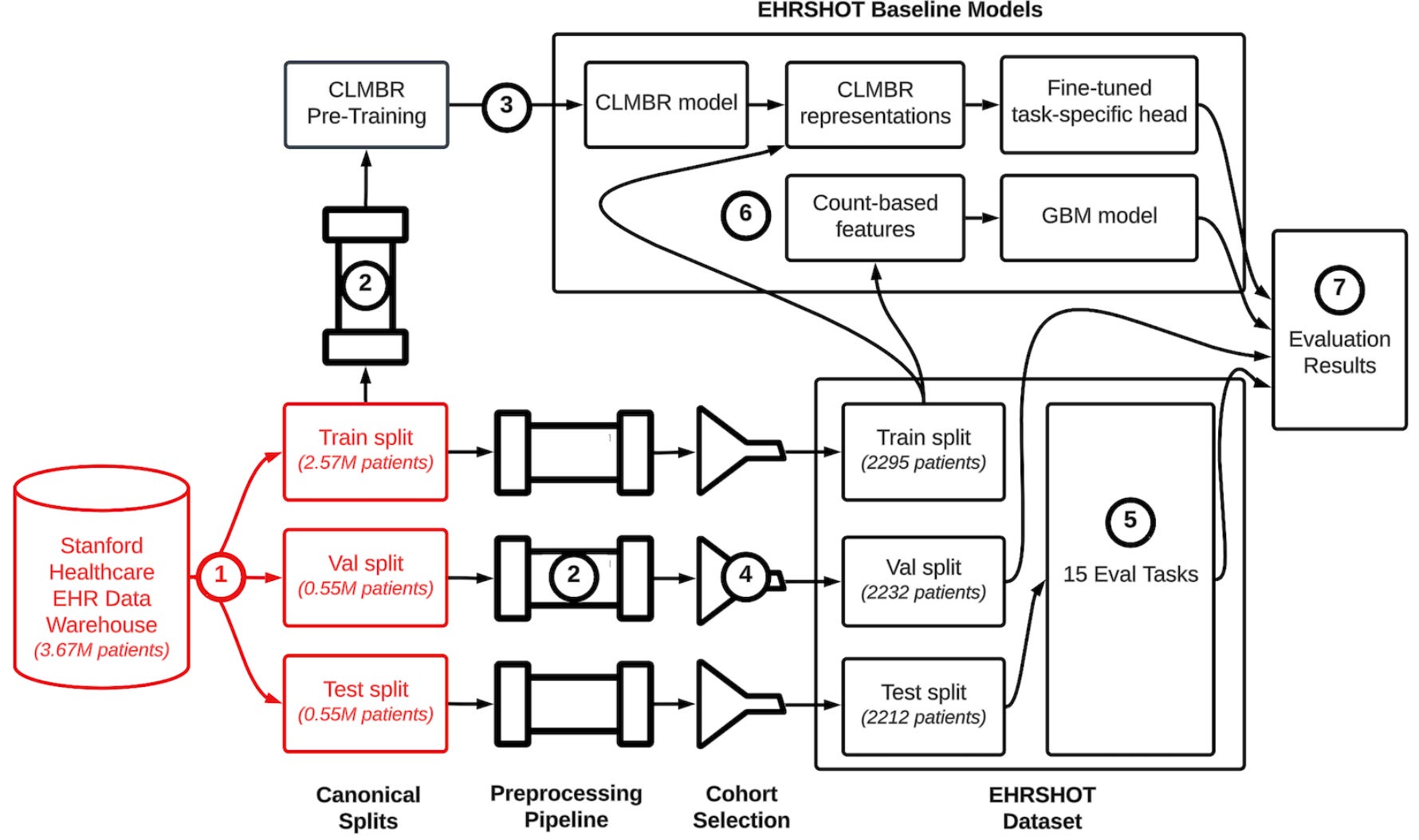
AI models can become as good as the data used for training. Then … how easy is to find open-source clinical data? Yesterday it was difficult, today we have EHRSHOT, a dataset of 6,739 de-identified longitudinal EHRs based on OMOP! EHSHOT comes equipped with data, bechmark and models!
📌 The data: 6,7k patients from Stanford Medicine with 41M clinical events across 920k visits, beyond the typical emergency and intensive care units. The power of this dataset is the longitudinal data, with 100+ visits per patient, which allows to train long-term models!
📌 The benchmark contains 15 prediction tasks, split between operational outcomes (e.g. predict ICU transfer), anticipating lab results (e.g. predict anemia), assignment of new diagnoses (e.g. lupus or pancreatic cancer) and anticipating chest X-ray findings
📌 The model (CLMBR-T-base) has 141M parameters and was trained on 2.6M deidentified EHRs to predict the next code in a patient’s timeline given their previous codes
New language model for therapeutics 💊
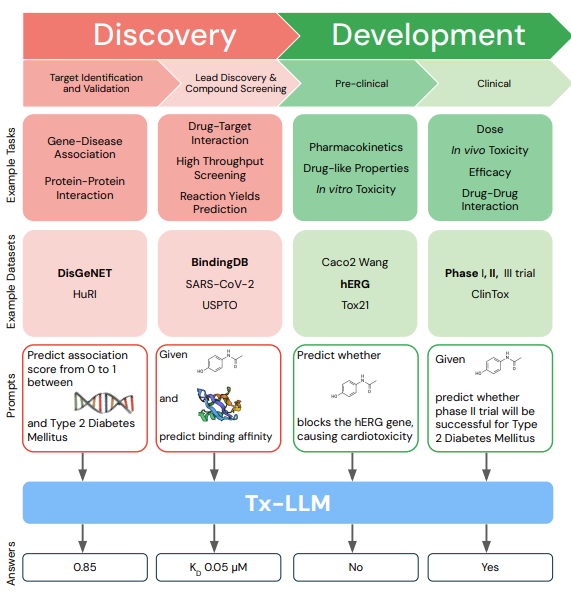
The road to develop new therapeutics is a long one, with many steps and hurdles along the way. AI can help along this journey. Researchers from Google developed Tx-LLM, a large language model fine-tuned from PaLM-2, designed to handle a variety of tasks across the entire therapeutic development lifecycle!
📌 Tx-LLM is a generalist and is designed to understand a wide range of biological entities – small molecules, proteins, DNA, cell lines, diseases – interleaved with free-text across 66 therapeutic tasks.
📌 Tx-LLM is trained using a comprehensive collection of 709 datasets targeting 66 different tasks, encompassing stages from drug discovery to clinical trials
📌 Tx-LLM achieves state-of-the-art (SOTA) or near-SOTA performance on 43 out of 66 tasks, such as
Looking forward to seeing more groundbreaking models like this one!

Life Science tools of the week 🛠️
1/ BindGPT
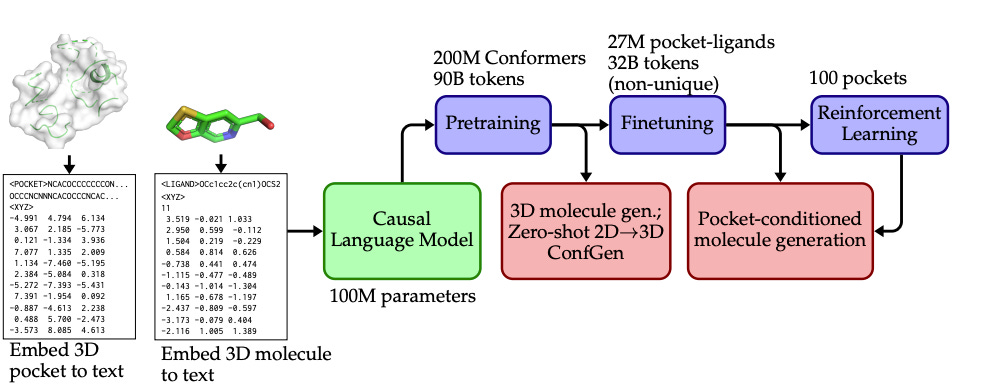
New model from InSilico Medicine! BindGPT, while still in a PoC stage, aims to predict proteins’s binding site to generate potential new drugs.
📌 BindGPT matches the performance of current state-of-the-art models on 3d structures, bonds and rings, while having comparable performance for druglikeness
📌 The magic behind BindGPT is to embed the 3D pocket as text AND applying reinforced learning after the pre-train/fine-tune. Why? To use the knowledge distilled into the model from massive amounts of less structured data.
📌 Unfortunately, the model is not open-source!
🔗 Paper
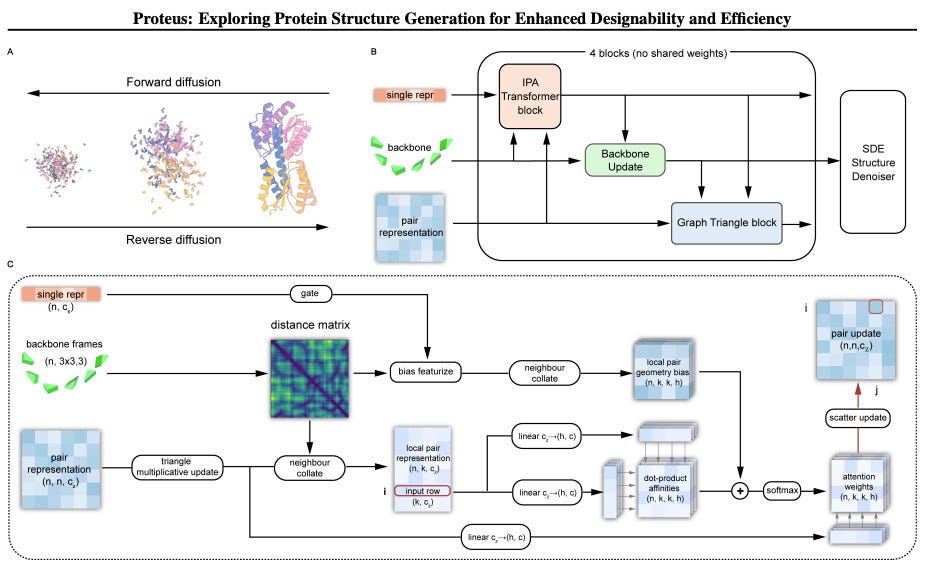
2/ Proteus - De novo protein
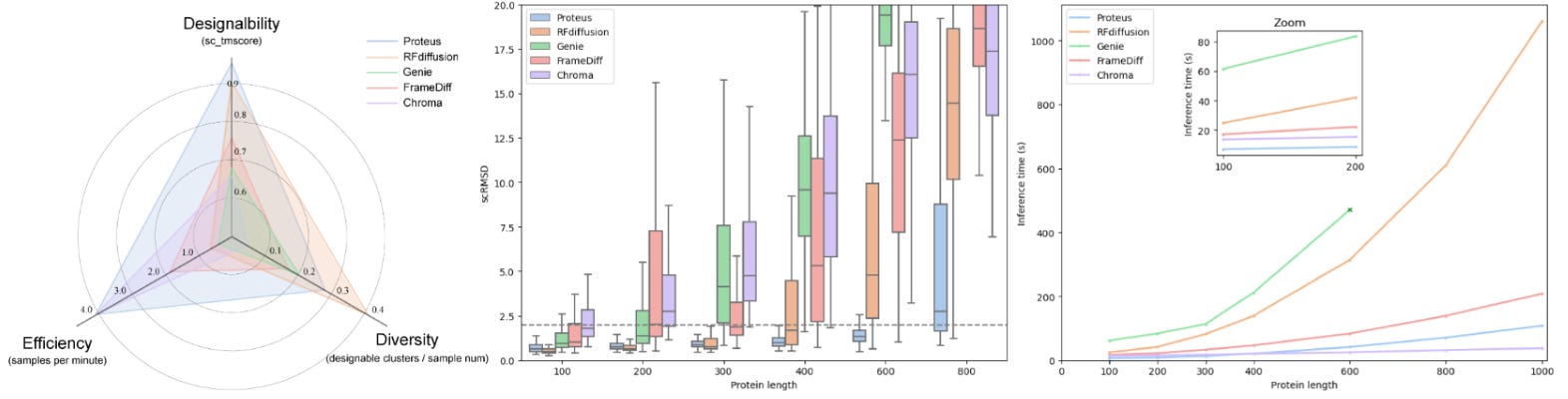
Another week has passed … and another protein model has been released! Proteus uses a diffusion method trained on 50,773 single-chain proteins form PDB to generate de novo protein backbones … but at a fraction of the speed of state-of-the-art models!
📌 Proteus shows amazing performance where it can generate a protein of up to 1000 amino acids in less than 3 minutes, compared to other tools like RFdiffusion which takes 8+ hours!
📌 Proteus has a designability (i.e. the likelihood of identifying a protein sequence to fold into the designated structure.) compared to RFdiffusion
📌 However, Proteus still needs to improve on the diversity, i.e. the ratio between designable structure clusters to the total number of generated backbones.
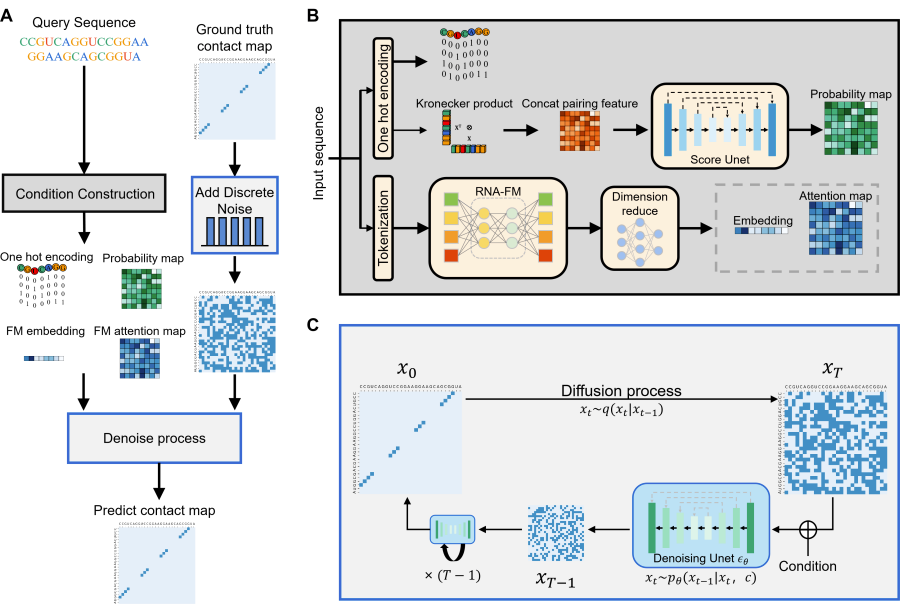
3/ RNADiffFold - RNA structure prediction
Introducing RNADiffFold, a new exciting model using Diffusion to predict the secondary structure of RNA! Why is important?
📌 RNA secondary structure is important to understand how RNA molecules interact within the cell and how they cause or are implied in diseases
📌 RNADiffFold uses discrete diffusion framework that treats RNA secondary structure prediction as a pixel-level segmentation task. Why? Because this better captures the distribution of secondary conformations!
📌 RNADiffFold shows higher precision compared to previous methods across a variety of datasets and it works well with sequences up to 500 nucleotides
BITE-SIZED COOKIES FOR THE WEEK 🍪
If you are in need of generating synthetic data for your needs, look no further! NVIDIA introduced Nemotron-4, a 340B parameter LLM which generates high-quality synthetic data across various domains to help increasing the performance and robustness of custom LLMs
GSK acquires tiny RNA startup Elsie for $50M, boosting its grand plans for developing RNA drugs
Long-term data for the first approved CRISPR gene therapy (Casgevy for sickle cell disease) show consistent efficacy and durability of the treatment!
Pfizer is on track to have 8 cancer drug blockbuster by 2030!
Don’t forget to take our short survey to help us understand how you currently use AI in your day-to-day!