
#9: Life Science x AI

Welcome back to your weekly dose of AI news for Life Science!
Here’s what we have for you this week:
The Rise of Hypothesis-Driven Artificial Intelligence in Oncology 🤖
New genomic benchmark dataset 💿
Life Science tools of the week 🛠️
The Rise of Hypothesis-Driven Artificial Intelligence in Oncology 🤖
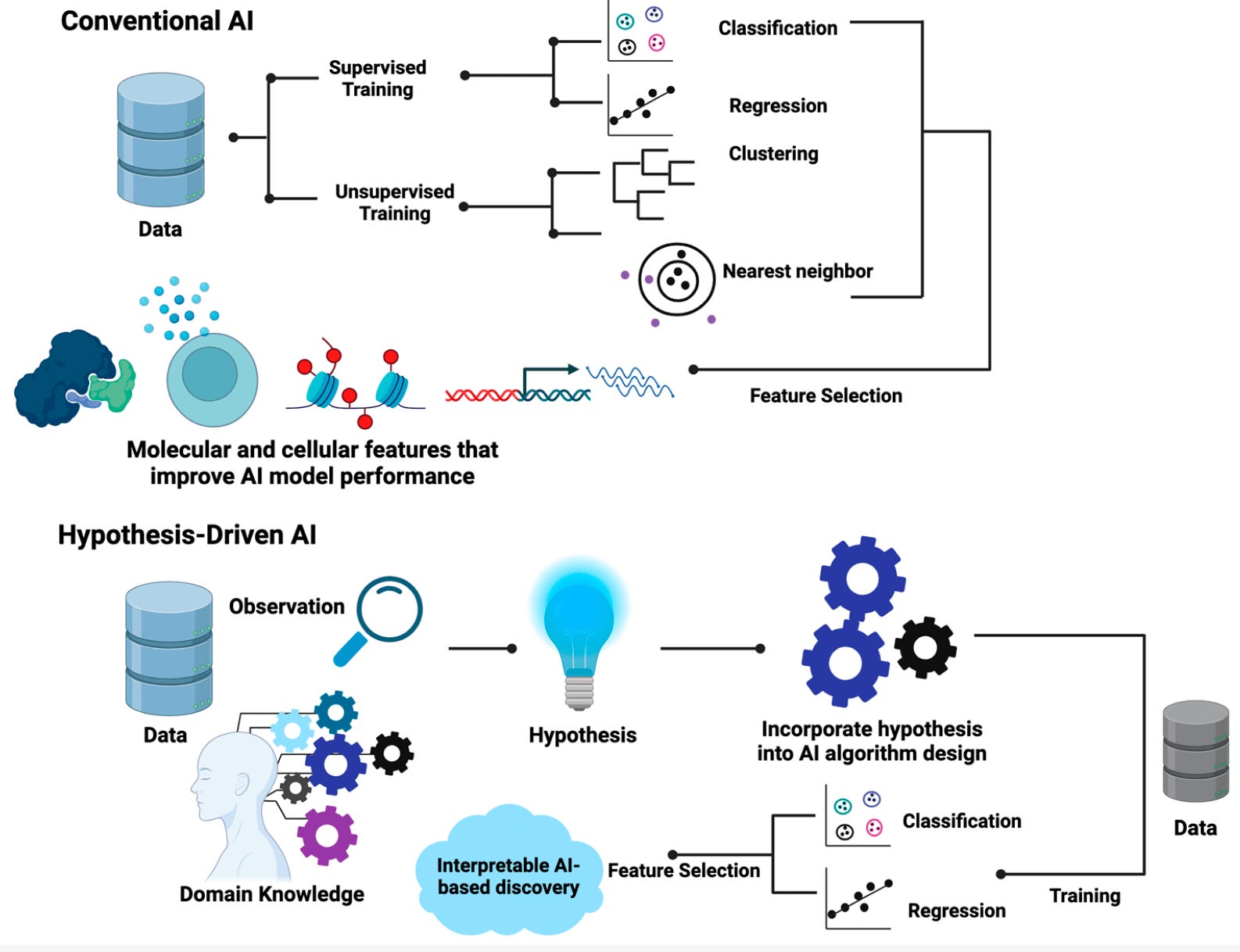
There are a lot of AI models in oncology BUT most models are focused on prediction tasks (e.g. is this molecule gonna have an effect on this cancer? is gene X linked to cancer? …) BUT these models still rely on scientific hypotheses generated by researchers. Scientists from Mayo Clinic provide a powerful review on hypothesis-driven AI ie. AI models which incorporate domain knowledge and hypotheses! Key insights 👇
📌 Main advantages of hypothesis-driven AI: i) More explainable results due to the focused underlying hypotheses being tested; ii) Less resources / Training data needed since specific scenarios are tested
📌 Few hypothesis-driven AI models have been developed to find chemical fingerprints linked to drug response (e.g. TuringBot , AI Feyman), decipher new cancer genes (MALANI algorithm) and better classify tumour (OncoNPC)!
Our take? For sure an field of the rise and we look forward to see better hypothesis-driven models in the next years!
New genomic benchmark dataset 💿
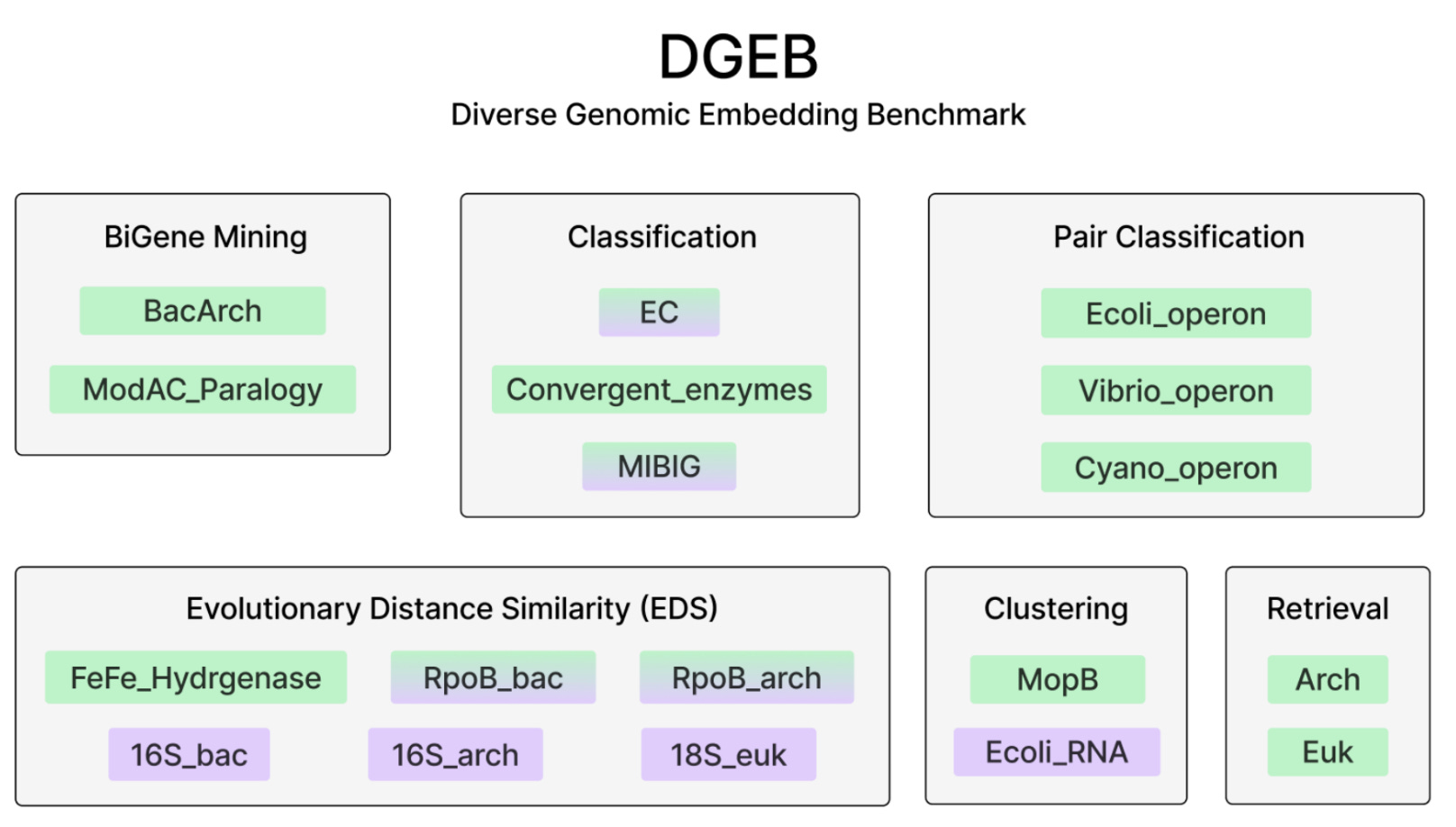
🚀 Always great to read about new benchmarks for biological language models (which are really needed). Here we introduce the latest Diverse Genomic Embedding Benchmark (or DGEB). The idea of DGEB is to evaluate how different embeddings affect the performance of protein language models (pLMs) and genomic language models (gLMs) on classification of various genomic motifs like regulatory elements, chromatin features, splicing, mutation fitness prediction 👇
📌 DGEB features 18 expert-curated datasets covering 117 phyla across Bacteria, Archaea and Eukarya.
📌 DGEB supports 6 different embedding tasks evaluation (Classification, BiGene mining, Evolutionary Distance Similarity (EDS), Pair classification, Clustering, and Retrieval.)
📌 The benchmark on 19 models trained on proteins (eg. ESM2, ProGen2, ProtTrans) and genomic data (Evo, Nucleotide Transformer) show that there is no single model that performs well across all tasks.
For a list of all dataset included check out the official paper!
Life Science tools of the week 🛠️
1/ H-Optimus - Pathology
Bioptimus, one of the latest startup applying GenAI in Life Science that raised $35M last February has already their first model! Introduce H-Optimus, the world’s largest open-source AI foundation model for pathology!
📌 H-Optimus is trained on a proprietary dataset of several hundreds of millions of images extracted from over 500k histopathology slides across 4k clinical practices and 200k patients
📌 H-Optimus has 1.1 billion parameters
📌 H-Optimus beats SOTA models across most of the Tile-level evaluations (identify tissue types or tissue characteristics on the tiles), Slide-level evaluations (binary classification detect the presence of biomarkers or the presence of metastasis) and
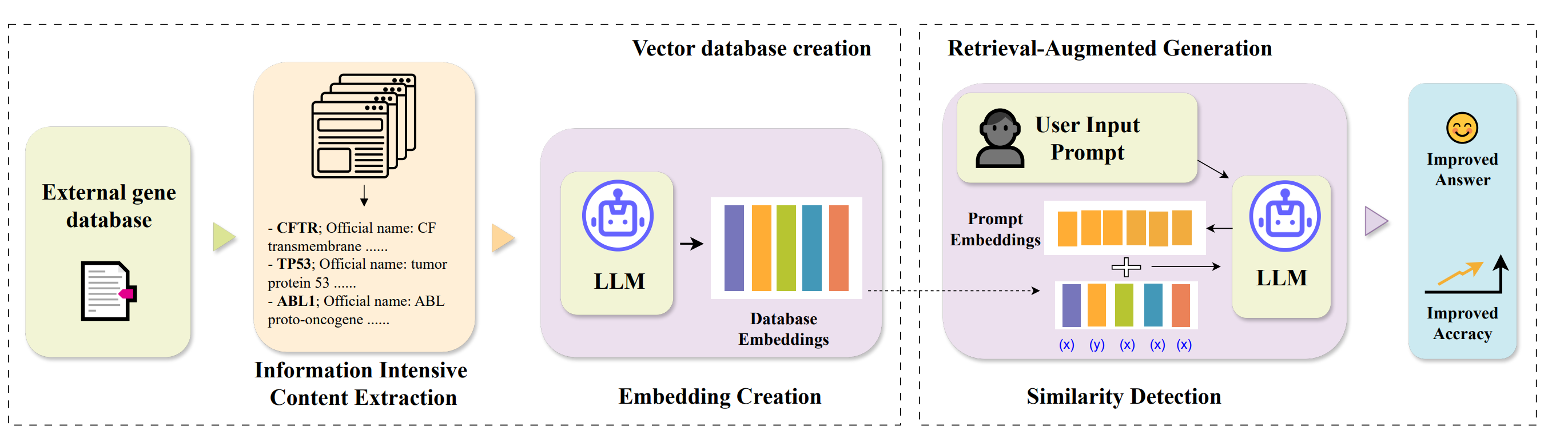
2/ GeneRAG - Retrieving gene information
ChatGPT used by all of us, most of the days. However, when used for research it is not there yet, especially for understanding and answering correctly questions around genes. That’s where GeneRAG comes into play! 👇
📌 GeneRAG applies Retrieval-Augmented Generation (RAG), of the latest GenAI techniques to integrate gene information dynamically
📌 GeneRAG offers several improvements over GPT-3.5/GPT-4: 39% in answering gene questions, 43% performance increase in cell type annotation, 25% decrease in error rates for gene interaction prediction
3/ ProteStAr - Protein compression
With many models requiring larger and larger datasets for training, it is important to keep on eye on the cost and the storage needs. Luckily, there are researchers out there working to improve data storage! Introducing Protein Structures Archiver (or ProteStAr) 👇
📌 Offers a 4x compression over gzip (standard library to compress data) while supporting all the major protein data types PDB, mmCIF, PAE (JSON) files
📌 Where is the magic 🪄? ProteStAr proposes a novel approach to predicting atom coordinates on the basis of the previously analyzed atoms, allowing to encode and compress the atom coordinates efficiently
📌 The tool (un)compresses with speeds of about 1 GB/s and in 30 hours it compresses the entire ESM Atlas (v0, ~600M structures) from ~67.7 TB to 3.8 Tb
🔗 Paper
🔗 Code
BITE-SIZED COOKIES FOR THE WEEK 🍪
If you want to understand better the economics of the current “AI Bubble” check out the report from Axios!
Want to understand what are the key ingredients for GenAI success in pharma? Check out this article from Dr. Dennis Janning on Process Knowledge!
Don’t forget to take our short survey to help us understand how you currently use AI in your day-to-day!