
AI in Life Science: Weekly Insights
Weekly Insights | July 15, 2025

In this issue:
Welcome back to your weekly dose of AI news for Life Science!
This week, we have some exciting new models lined up for you:
RNAGenesis: A Generalist Foundation Model for Programmable RNA Therapeutics 🧬
PROTAC-Splitter: Automating Substructure Identification for Targeted Protein Degraders 🧩
SAAINT-DB: A Comprehensive Structural Antibody Database for Modeling and Design 🧫
Dive into these game-changing innovations and explore how they are transforming the biotech and healthcare space!
What’s slowing you down? Let us tackle it.
RNAGenesis: A Generalist Foundation Model for Programmable RNA Therapeutics 🧬
Designing functional RNA molecules from aptamers to guide RNAs means understanding sequence, structure, and function all at once. While recent RNA models can represent these features, few can generate real lab-tested candidates. RNAGenesis tackles that gap with a unified foundation model that links RNA sequence, folding, and function for practical therapeutic design. By combining a BERT-style encoder with a latent diffusion decoder and gradient-guided design, RNAGenesis shows strong performance for antisense oligos, aptamers, and genome editing scaffolds, backed by experimental data.
🔬 Applications
Programmable RNA Therapeutics - Designs antisense oligos, siRNAs, shRNAs, circRNAs, aptamers, and sgRNA scaffolds for gene regulation and editing.
Structure-Aware Design - Handles inverse folding, 3D prediction, and de novo folding with high accuracy.
Zero-Shot Genome Editing Boost - Generates sgRNA scaffolds that improve CRISPR, base editing, and prime editing efficiency without extra training.
📌 Key Insights
Benchmark Leader - Outperforms on 11 of 13 BEACON tasks with 97.8% accuracy for non-coding RNA function and R² of 89% for alternative polyadenylation prediction.
Experimental Results - RNAGenesis aptamers bind with affinities as low as 4.02 nM, about 3 times stronger than SELEX controls, and sgRNA scaffolds boost editing up to 2x.
Broad Potential - Achieves AUROC above 0.8 on siRNA prediction and significant gains for shRNA design and UTR variant pathogenicity.

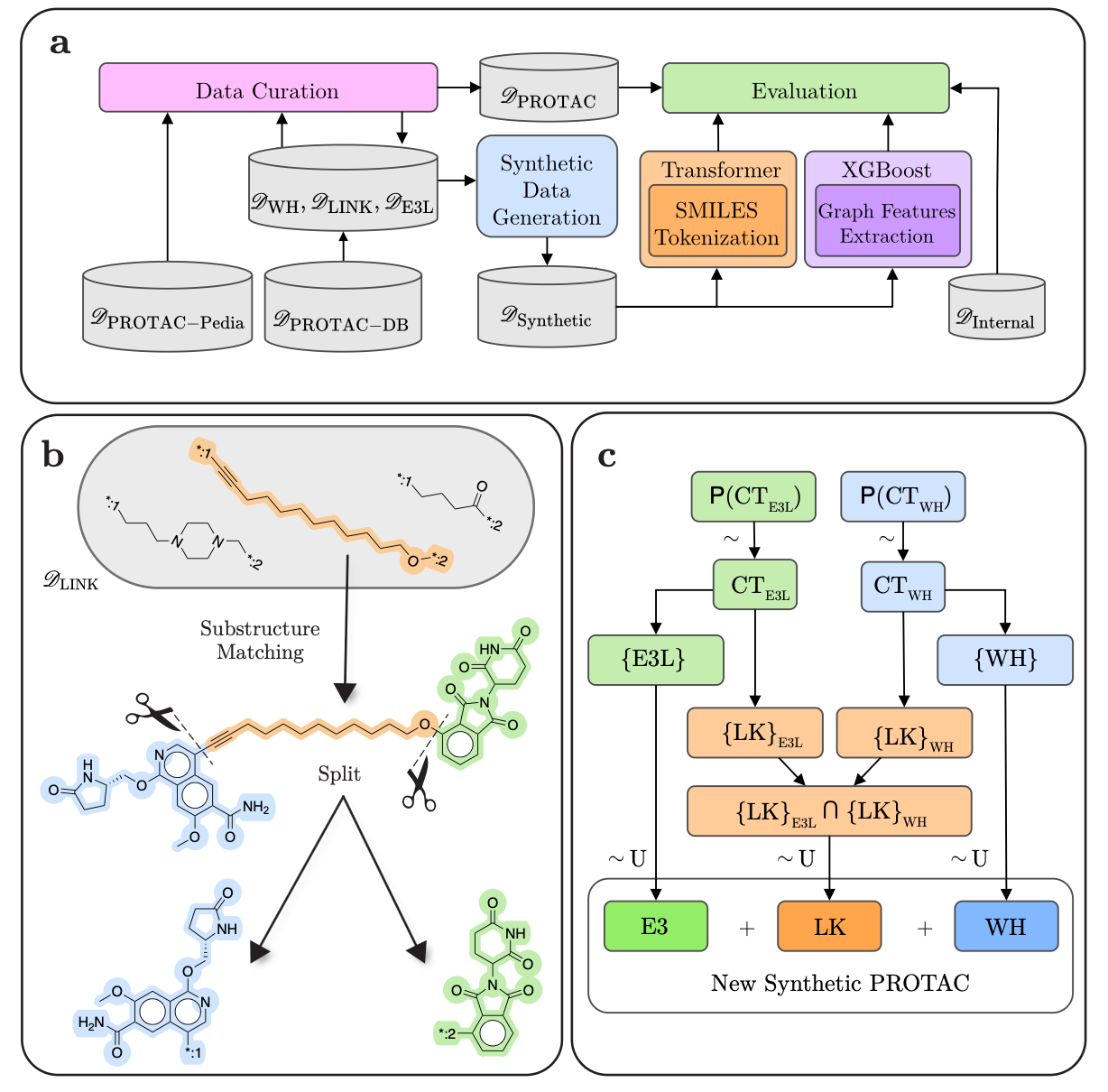
PROTAC-Splitter: Automating Substructure Identification for Targeted Protein Degraders 🧩
Designing PROTACs means splitting each molecule into the warhead, linker, and E3 ligase ligand accurately, but this has been time-consuming and error-prone. PROTAC-Splitter fixes that by using a machine learning pipeline to automate clean, chemically valid splitting even for new chemistries. It trains on a massive new synthetic set of 1.3 million labeled PROTACs, using a Transformer for sequence patterns and a graph-based XGBoost model for robust fallback on novel structures.
🔨Applications
Scalable Annotation - Automatically extracts warheads, linkers, and ligands for large PROTAC libraries, freeing chemists from manual curation.
Stronger Downstream Models - Provides clean inputs for designing linkers, predicting ternary complexes, and building degradation activity predictors.
Open and Flexible - Works on proprietary and public PROTACs with open code and training sets for other teams to adapt.
📌 Key Insights
High Accuracy - Achieves 86% exact match and 96% reassembly accuracy on public PROTACs, with XGBoost fallback ensuring 100% chemical validity.
Handles Novel Chemistry - Fallback XGBoost keeps splits valid on AstraZeneca’s test set, where the Transformer alone drops to 18% match.
Largest Synthetic Data - Comes with a 1.3 million compound synthetic set plus reusable code, filling a key data gap for degrader ML.

SAAINT-DB: A Comprehensive Structural Antibody Database for Modeling and Design 🧫
Antibody design and modelling rely on high-quality structure and interaction data, but even top databases like SAbDab have gaps and misclassifications. SAAINT-DB raises the bar with a new workflow (SAAINT-parser) that scans the full PDB, detects chains and pairs with high accuracy, and curates binding affinities. With more non-redundant antibody-antigen entries than SAbDab and fine-grained type classification, it gives modellers a better foundation for training or design tasks.
🔨Applications
Better Antibody Models - Includes 19,128 curated entries from 9757 PDB structures, covering antibody-only and antibody-antigen complexes. Ideal for training and validating structural prediction, docking, and generative design tools.
Precise Pairing and Formats - Accurately detects heavy-light chain pairs, assigns 29 distinct antibody formats, and includes over 1,400 unique antigen-binding records, supporting diverse modeling use cases across species and engineered constructs.
Fully Open - Provides an open-source parser (SAAINT-parser), fully annotated structural models, and machine-readable CSV files, enabling seamless integration into AI model pipelines and reproducible benchmarking.
📌Key Insights
Twice the Binding Data of SAbDab - SAAINT-DB includes 1444 non-redundant affinity records, nearly 2× more than SAbDab's 736, with clean PDB chain pairing and clear antigen classification for training ML models.
Accurate and Scalable Pairing - Combines rule-based heuristics with interface residue scoring, achieving >90% pairing accuracy on complex structures with <2% error across tested entries — resolving many edge cases that existing tools leave ambiguous.
Detailed Typing Across 29 Structural Classes - Antibodies are categorized into 29 formats, including FabH:FabL (59%), VH:VL (21%), VHH-only (9%), and scFv/diabody formats thus giving researchers greater precision for format-specific design, docking, or model pretraining.

Did you find this newsletter insightful? Share it with a colleague!
Subscribe Now to stay at the forefront of AI in Life Science.
Connect With Us
Have questions or suggestions? We'd love to hear from you!
📧 Email Us | 📲 Follow on LinkedIn | 🌐 Visit Our Website