
Google's AMIE, Stanford's CANVAS, and Vermont's AMPGAN v3
Kiin Bio's Weekly Insights

Welcome back to your weekly dose of AI news for Life Science! This weeks fix:
Google’s AMIE system matched or beat primary care physicians on clinical management reasoning across 100 multi-visit scenarios. Published in Nature, and the study design is more rigorous than most in this space.
CANVAS turns standard H&E slides into virtual spatial proteomics maps, predicting tumour microenvironment neighbourhoods from cheap histology. Validated across 5,000 patients and 9 cancer types.
AMPGAN v3 is the first generative model for antimicrobial peptides that handles non-canonical amino acids and chemical modifications. Two of five generated candidates showed real antimicrobial activity. They also built an agentic pipeline around it, which is where this gets interesting.
Kiin Pioneer Programme
We built a platform that helps researchers speed up their entire science, from literature review and biomarker discovery to bioinformatics and computational chemistry. If your workflow involves pulling findings from five different places before you can actually act on any of them, this is for that.
The Pioneer Programme gives academic labs and non-profits one year of free access, plus support from our science team. No cost, no data transfer, all IP stays with your institution. Applications close August, cohort starts September.

AMIE: Conversational AI for disease management
🧪 Where This Fits
Most AI-in-medicine papers test whether a model can diagnose from a static vignette. That is a solved problem at this point, or at least a well-explored one. What has not been tested seriously is whether an AI system can manage a patient over time: adjust treatment plans across multiple visits, respond to new lab results, and prescribe medications safely. That is what primary care actually involves, and it is where AMIE (Articulate Medical Intelligence Explorer) from Google DeepMind now enters.
Previous AMIE work showed the system could match physicians on diagnostic conversations. This paper extends it to management reasoning, which is harder because it involves sequential decisions, guideline interpretation, and medication safety. The comparison set is interesting: 21 board-certified primary care physicians across 100 multi-visit case scenarios grounded in UK NICE and BMJ Best Practice guidelines.

🔍 What It Is
Management reasoning for longitudinal care is largely untested for AI. Liévin et al. from Google DeepMind present an agentic version of AMIE optimised for multi-visit clinical management and medication reasoning.
Uses Gemini’s long-context window to combine in-context retrieval of clinical guidelines with structured reasoning. A multi-agent architecture handles dialogue, management planning, and medication lookup from drug formularies (OpenFDA, BNF).
In a blinded virtual OSCE study, AMIE scored significantly higher than PCPs on treatment preciseness (96% vs. 62%, p<0.001) and guideline alignment (93% vs. 75% by visit 3). On the RxQA medication benchmark, AMIE outperformed PCPs on harder questions (57.9% vs. 47.8%, p<0.001). Specialist physicians and patient actors preferred AMIE 47% of the time vs. 7% for PCPs.
💡 Why This Is Cool
The honest reaction here is: this is impressive and somewhat uncomfortable. AMIE is not just pattern-matching against guidelines, it is reasoning about how to adjust a plan given what happened at the last visit. The study design (blinded OSCE, specialist evaluators, real guidelines) is more credible than most in this space. The medication reasoning results are particularly notable because prescribing errors are a leading cause of preventable harm. That said, this is still a virtual scenario, not a real clinic with real patients who do unexpected things. The gap between “performs well in structured evaluation” and “can safely manage my mum’s hypertension” remains large. What this does establish is that the technical capability exists. The regulatory and deployment questions are now the binding constraint, not the model performance.
📃 Read the paper.
💻 Try the code.
CANVAS: Virtual spatial tumor profiling from histopathology
🧪 Where This Fits
Spatial proteomics (CODEX, MIBI, etc.) can map the tumour microenvironment at single-cell resolution, but it costs thousands per sample and requires specialised equipment. Standard H&E histopathology costs almost nothing and is already collected for every cancer patient. The question is whether you can infer the spatial biology from the cheap stain. Previous attempts have tried to predict individual protein expression from H&E, but that approach is fragile: sensitive to staining variation, limited to a handful of markers, and accuracy drops quickly. CANVAS takes a different approach, predicting cellular neighbourhood patterns rather than individual proteins, which is a more robust prediction target.
This connects to a broader trend in computational pathology where foundation models (UNI, Virchow, CONCH) have made feature extraction from H&E much more powerful, and the question is now what downstream tasks those features can support. CANVAS uses these pretrained features to bridge modalities rather than training from scratch.
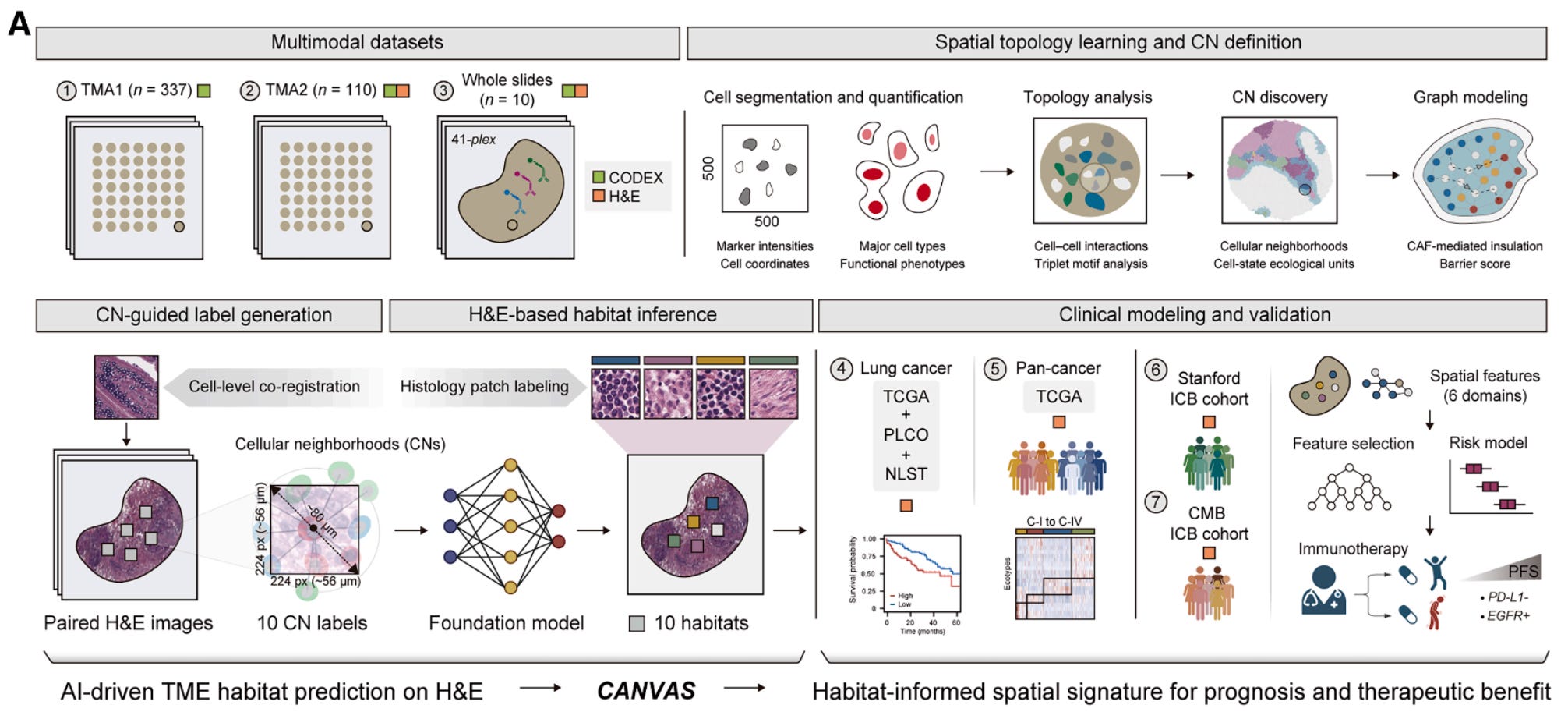
🔍 What It Is
Spatial proteomics reveals the tumour microenvironment in detail but costs too much to scale. Li et al. from Stanford present CANVAS, an AI platform that predicts spatial cellular neighbourhood structures directly from standard H&E slides, trained on an atlas of 18 million cells profiled by 41-plex CODEX imaging.
CANVAS defines 10 reproducible cellular neighbourhoods from CODEX data across 457 lung cancer patients, then trains a pathology foundation model to predict these neighbourhood patterns from co-registered H&E images. It operates at the ecological niche level rather than individual cell types.
Applied to over 5,000 patients across 9 cancer types, CANVAS-derived spatial features predicted immunotherapy response with AUCs above 0.75 at 6, 12, and 24 months. The spatial signature stratified patients by progression-free survival (HR = 2.42, p<0.001) and outperformed established biomarkers including TMB, PD-L1 expression, and TLS. Validated externally on a Cancer Moonshot Biobank cohort.
💡 Why This Is Cool
This matters for a specific reason: immunotherapy response prediction is a clinical problem where existing biomarkers (PD-L1, TMB) work poorly. About 20-30% of patients respond to checkpoint inhibitors, and we are bad at predicting who they will be beforehand. CANVAS proposes that the spatial organisation of the tumour microenvironment, inferred from a slide that already exists in every pathology lab, is more informative than the molecular markers we have been relying on. If the external validation holds up across broader cohorts (the Moonshot cohort is small at n=40), this could actually change who gets prescribed immunotherapy. The non-commercial license limits immediate industry adoption, but for academic cancer centres this is usable now.
📃 Read the paper.
💻 Try the code.
AMPGAN v3: Agentic discovery of non-canonical antimicrobial peptides
🧪 Where This Fits
Antimicrobial resistance causes over a million deaths annually, and no new antibiotic class has been commercialised since 2000. Antimicrobial peptides (AMPs) are attractive because they disrupt membranes through physical interactions, making resistance harder to develop. Generative models for AMP design exist (PepGAN, HydrAMP, AMP-Designer), but they all share two limitations: they only work with natural L-amino acids, and they require manual filtering of outputs. Real therapeutic peptides need D-amino acids and terminal modifications to survive in the body. AMPGAN v3 is the first generative model that handles these non-canonical chemistries, and PepCraft wraps it in a multi-agent pipeline that automates the filtering.
The field has been generating lots of candidate peptides computationally, but the translation gap to actual antimicrobials has been wide. Most papers stop at predicted activity scores. This one synthesises candidates and tests them against real bacteria, which is the bar that matters.
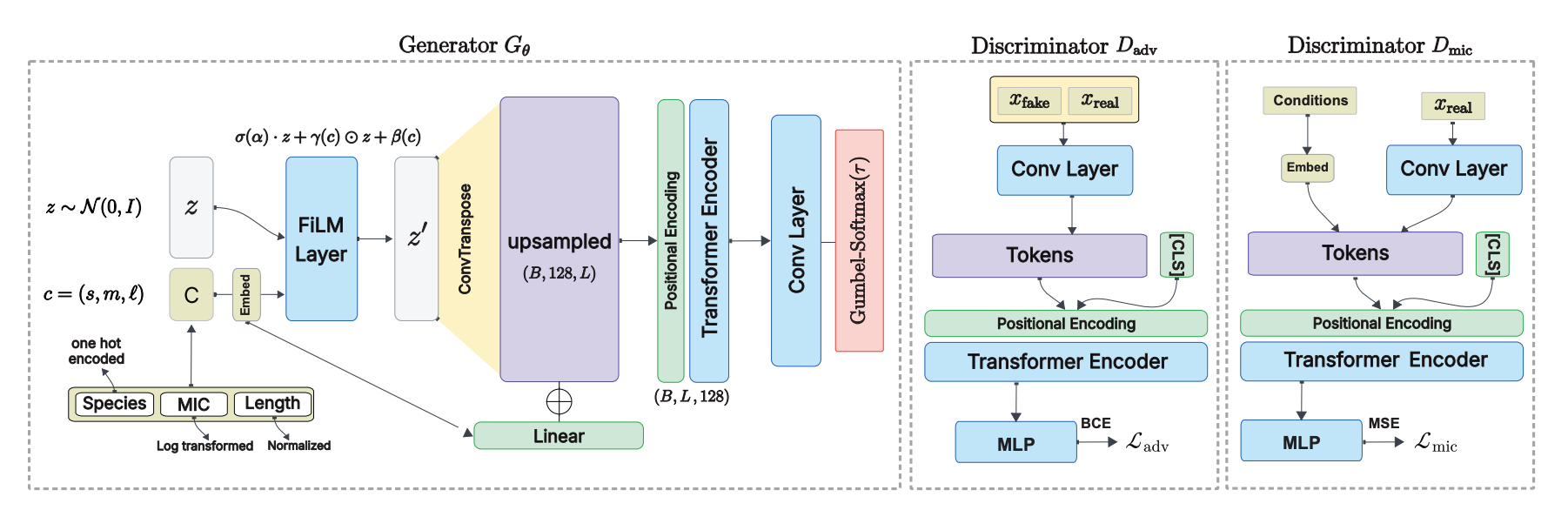
🔍 What It Is
Generative models for antimicrobial peptides are limited to natural amino acids and produce outputs that need extensive manual curation. Jung et al. from the University of Vermont and Purdue present AMPGAN v3, a conditional GAN that generates antimicrobial peptides with D-amino acids and terminal modifications, paired with PepCraft, a multi-agent framework for automated AMP discovery.
AMPGAN v3 separates adversarial training across two discriminators: one for sequence realism, one for antimicrobial activity prediction. This fixes the training instability that plagued earlier versions (only ~10% of AMPGAN v2 runs produced usable models). PepCraft uses a Planning Agent to coordinate specialised executors for generation, physicochemical filtering, and database verification.
Two of five synthesised candidates showed clear antimicrobial activity against Gram-positive strains, with the best reaching MIC of 8 μg/mL against B. subtilis. The candidates spanned three structural classes (alpha-helical, beta-hairpin, random coil) and incorporated D-amino acids and amidation, which previous generative methods cannot produce. PepCraft’s prioritisation recommendations aligned with the wet-lab results.
💡 Why This Is Cool
The wet-lab hit rate (2/5) is respectable for a generative model, and the chemical space expansion is the real contribution. Every other AMP generator is restricted to natural amino acids, which means their outputs degrade rapidly in serum. Expanding the vocabulary to include D-amino acids and terminal caps makes the generated peptides actually viable as therapeutics rather than just interesting sequences. The agentic pipeline (PepCraft) is early-stage and exploratory, but it points toward a pattern we will see more of: generative models wrapped in verification agents that can filter, cross-reference, and prioritise without human intervention. This was accepted at the ICML 2026 GenBio workshop, not a top venue, and the validation is limited to Gram-positive bacteria. Worth watching, not yet proven at scale.
📃 Read the paper.
💻 Try the code.
🗓️ Events & Competitions
The best competitions, hackathons, and community challenges in AI x life sciences, curated weekly. Know something worth featuring? Reply and let us know.
More upcoming events:
Creative Disruption Forum: Modern Drug Discovery | June 18, NIAB Cambridge
A full-day forum for biotech and R&D leaders exploring how technology is changing small molecule drug discovery. Keynote interviews with industry thought leaders followed by workshops under Chatham House Rules, limited to 60 attendees. Part of Cambridge Wide Open Week. Organised by Graham Combe and Prof Tony Sedgwick. £60 for biotech companies.
London Protein Design Day | June 23, Imperial College London
The first edition of a one-day symposium bringing together London’s protein design community and beyond. Programme spans AI-driven design, molecular dynamics, and bioinformatics, with applications across enzymes, antibodies, and materials. Organised by Pietro Sormanni, Rebecca Birolo, and Jakub Lála. In person only.
BioHackathon Europe 2026 | November 9-13, Barcelona
ELIXIR’s annual international bioinformatics hackathon, running since 2018. 160+ participants, five days of collaborative coding on open bioinformatics infrastructure and tools. The call for project proposals has now closed.
Thanks for reading!
💬 Get involved
We’re always looking to grow our community. If you’d like to get involved, contribute ideas or share something you’re building, fill out this form or reach out to me directly.
Connect With Us
Have questions or suggestions? We'd love to hear from you!
📧 Email Us | 📲 Follow on LinkedIn | 🌐 Visit Our Website