
🥼 Luvida: Bringing the Whole of a Patient’s Life Into Clinical Trials
Deep Dive | Edition 16

Welcome back to the deep dive, where we break down the AI tools and data reshaping how new drugs are discovered. In each edition, we speak directly with the teams behind these tools to explain what they solve, how they work and where they are going next.
Keeping up with AI x life science news can get exhausting.
It’s scattered across LinkedIn, X, Substack, arXiv, Slack, newsletters... and you still somehow miss the things that actually matter. Too much noise, not enough signal.
We’re building something to fix that: a smarter, more powerful way to stay on top of what’s actually relevant to you.
But we want to build it with you, not just for you. Take 2 minutes to tell us what’s missing. What you share will directly shape what we build, and you’ll be the first to benefit from it.
The failure rate in clinical development is well known but no less striking for it. Around 90% of clinical trials still fail. And buried inside that number is a problem the industry has not yet confronted: trials are still being designed on incomplete patient information, slowing recruitment, driving up attrition, and causing costly delays, ultimately putting medicines out of reach for the patients who need them most.
The industry spends an eyewatering $400 billion a year on that failure. And while the causes are multiple, a significant portion of that failure is traceable to decisions made at the protocol design stage, before a single patient is enrolled.
Trial teams are making high-stakes decisions about patient populations, eligibility criteria, endpoints, and recruitment strategies on a partial evidence base. Biology is well represented. But the patient’s life is not. The result is a systematic underestimation of the factors that actually determine recruitment and screening success, patient dropout, adherence, and the need for subsequent protocol amendments.
That’s the gap Luvida is building into.

We sat down with co-founders Hannah Amies and James Malone to understand what they’re working on. Hannah’s background spans biomedicine, consulting, head of product at BenevolentAI and epidemiology at Oxford. James brings computer science, bioinformatics, and a career spanning the European Bioinformatics Institute, his own acquired data curation company, and CTO roles at SciBite and Benevolent AI. Between them they cover both sides of the problem: the data science and the clinical domain knowledge.
🔴 The Problem
Clinical trial protocol design remains a surprisingly manual, consensus driven process for a field built on evidence. Getting a protocol ready involves assembling internal teams, bringing in external key opinion leaders, iterating over months, and more excel spreadsheets than are possible to manage. It can take up to 18 months, just for the design phase. And it’s not especially data-driven. “It’s very expert opinion driven,” James told us. “That can be very advantageous, you need that expertise. But it does mean biases creep in. Evidence is scattered across documents such as historical protocols, published literature, amendment documents, recruitment and on-trial data, and regulatory feedback. This is also a data problem.”
The result? Around 50% of trials end up requiring protocol amendments, averaging 3.3 per trial. Each one costs roughly $500,000 and burns at least three months waiting for regulatory sign-off. Do the maths across multiple trials per drug and you’re looking at hundreds of millions in lost on-patent revenue, and years of delay before a drug reaches a patient who needs it. “Most people working in the space are just doing it because they believe in getting good drugs into the right patients’ hands,” James said. That’s the real cost of a broken process.
📊 The Missing Data
The core issue is an incomplete patient picture. Clinical and biomedical data captures areas like biology, genotypic profiles, disease characteristics and prior treatment history. What it does not capture is the much broader set of variables that determine whether a given patient is recruited, adheres to treatment, or withdraws early.
The data exists, it is simply not being used. Hannah’s path to founding Luvida started not in a lab, but in Liverpool, implementing electronic patient records across three hospitals. That’s where she first noticed the gap: mountains of health data, almost entirely underleveraged. Epidemiology at Oxford sharpened the picture. “A lot of this stuff we have evidence for” she said, “but a lot of it is buried in research papers and not being leveraged at scale”
Luvida’s answer is what they call Electronic Life Records, a proprietary data layer that builds a more complete picture of the patient than clinical and biomedical data alone. It is that richer picture that changes what you can predict, and how accurately.
💡 The Idea: Expert in the Loop, Not AI in Charge
Luvida’s platform isn’t trying to replace clinical operations teams. James was clear: “We don’t want to come in and look like we’re replacing a clinical trial team of medical writers.” The goal is to speed up the parts of the job that involve synthesising signals from disparate, messy data sources, then hand that signal back to people who know what to do with it.
The platform works within a familiar authoring environment, think Google Docs-style interface, where AI-driven suggestions surface like comments: accept, reject, or edit. Every recommendation is tied directly to the evidence for review, which is used for decision-making and regulatory justification. There’s also a chat interface for question-answering. But the core of what Luvida does is pull together clinical and biomedical data, curated historical trial data, and patient lifestyle and behavioural data to flag where a trial is likely to fail before it starts.
Questions like: which populations are most likely to drop out? Where will recruitment stall? Are your eligibility criteria accidentally excluding a particular ethnic group? Does this background population have co-morbidities you haven’t accounted for? Is the evidence strong enough for regulatory review?
Crucially, it pairs AI pattern-finding with strict rule-based approaches. “AI is great at looking for big patterns,” James said, “but many modern models are trained to be helpful, which means they can sometimes infer things that aren’t really there.” So Luvida enforces rigour: everything is auditable, everything is traceable, and recommendations are evidence-based.
📢 Why It’s Different
For large pharma, Luvida gives teams the evidence base to navigate internal governance faster. Instead of one expert’s opinion against another’s, teams walk into meetings with data. For smaller biotechs who rely entirely on CROs and often feel, as Hannah put it, “pretty disempowered”, it’s even more significant. Luvida arms them with evidence to push back and ask better questions.
For rare diseases, where historical trial data is thin by definition, the platform can identify analogous disease areas and trials that work in adjacent spaces. “That’s something that AI is really good at identifying,” Hannah said. “The patterns. And that’s really where our models come into play.”
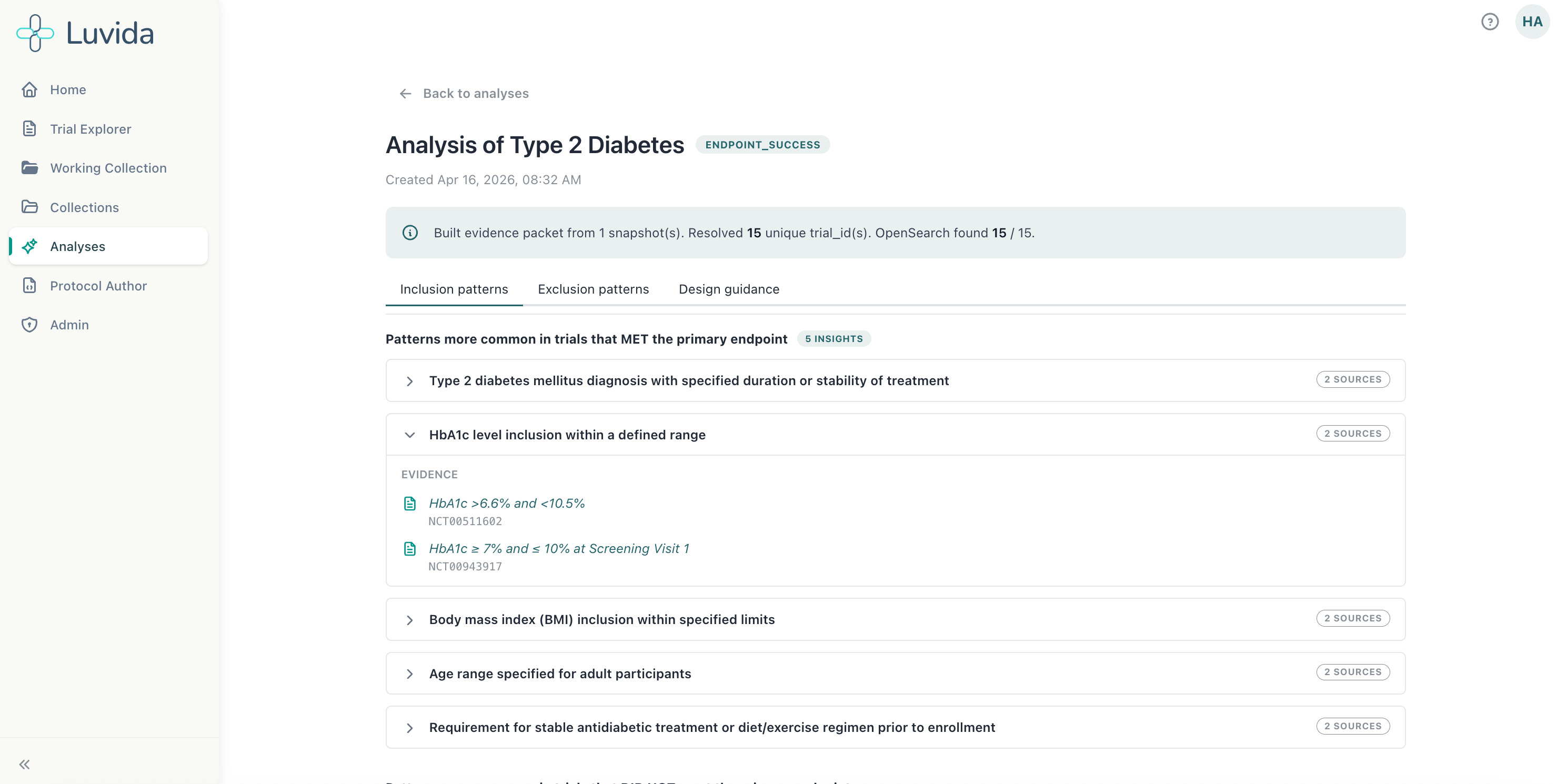
The early validation numbers are striking. When Luvida ran their models against past trials, feeding in initial protocols while blinding the system to the amendments that followed, it predicted 40- 50% of those subsequent amendments. In a prototype. The cost of each predicted amendment that doesn’t happen? Hundreds of thousands of dollars and three months of time.
🔮 The Future
Luvida is approximately a year old and is working with forward-thinking customers on live trial design programmes. Data is processed by indication to ensure data quality, a deliberate intention that keeps model outputs high quality and trustworthy. The platform already covers 500K+ trials, with 200K+ enriched with publications. From this, for example, we’ve already surfaced 87K+ known adherence risks.
The roadmap includes key opinion leaders contributing directly to the platform to streamline stakeholder management, and eventually patients too, to ensure the patient voice is brought in from the TPP, with protocols translated into plain language. Scenario modelling alternative trial designs enables pressure-testing of real-world on-trial risks before a trial even starts.
There’s also an API, so customers can plug Luvida into their own internal tooling and models, rather than adding another standalone system to an already crowded stack.
The platform is also designed with an eye on where regulation is heading, FDA diversity action plans and the NHS 10-year plan both point in the same direction: trials that are designed to reflect the real-world diversity of patient populations. Luvida’s richer patient picture makes that not just possible, but built in from the start.
The incomplete patient picture has been one of the industry’s most persistent and expensive blind spots for decades. Luvida is building the infrastructure to close it.

Get in touch
Luvida is headquartered in London and already partnering with CROs, pharma, and biotech across the EU and US. For a limited time, they’re offering exclusive value assessments. To see Luvida in action on one of your protocols, secure your spot at [email protected].
You can also learn more at www.luvida.co.uk

Thanks for reading Kiin Bio Weekly!
💬 Get involved
We’re always looking to grow our community. If you’d like to get involved, contribute ideas or share something you’re building, fill out this form or reach out to me directly.
Subscribe now to stay at the forefront of AI in Life Science and keep up with this upcoming season of deep dives.
Connect With Us
Have questions on this or suggestions for our next deep dive? We’d love to hear from you!
📧 Email Us | 📲 Follow on LinkedIn | 🌐 Visit Our Website