
MD-LLM-1, Meta's Brain-Aligned DINOv3, and FlowMol3 for Fast 3D Prediction
Kiin Bio's Weekly Insights

Welcome back to your weekly dose of AI news for Life Science!
What’s your biggest time sink along the drug discovery process?
MD-LLM-1: Predicting Protein Motion with Language Models
What If You Could Run Molecular Dynamics Using a Language Model?
Most protein dynamics tools are either accurate or fast, but rarely complete both well. Molecular dynamics (MD) is the gold standard, yet reaching rare conformational states can take days or weeks of compute time. Expensive.
MD-LLM-1 takes a different path. Built on Mistral 7B and fine-tuned with LoRA, it predicts protein conformational changes by treating them like language, using tokens, sequences, and attention to learn how structures evolve over time.
No physics engine, no force fields. Just a language model trained on MD trajectories and somehow, it still discovers states the original simulations never reached.
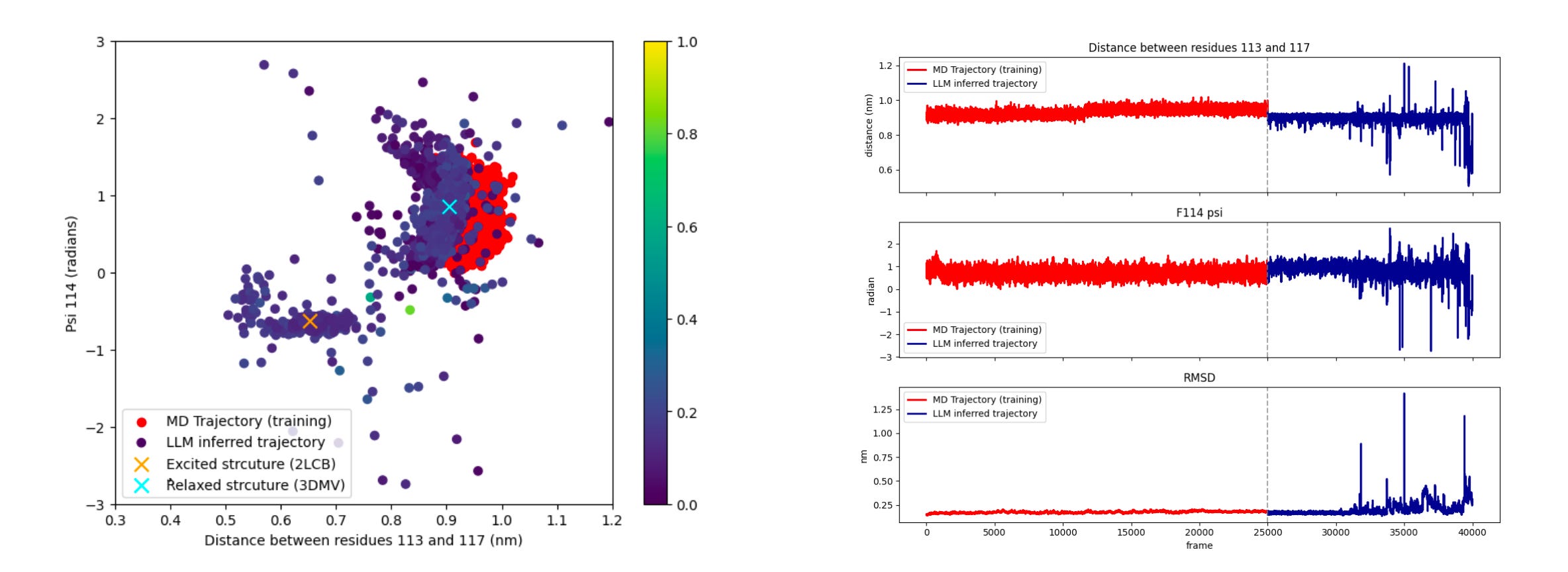
Applications and Insights
1. Cross-state discovery with limited data
Trained on short MD trajectories from a single conformational state of T4 lysozyme, MD-LLM-1 still discovered the alternative state. From the L99A native state (97 percent population), it generated excited state structures with 113-117 residue distances of 0.5 nm and ψ angles of -0.75 radians, matching the 3% excited state.
2. Bidirectional generalisation in protein dynamics
A separate model trained only on the triple mutant’s excited state (96% population) discovered native-like conformations of the single mutant. RMSD stayed below 0.3 nm throughout, showing stable, high-quality structure while transitioning across states.
3. State transitions in larger, flexible proteins
MD-LLM-1 trained on closed-state Mad2 discovered features of the open state, shifting residue 171-174 distances from short to extended and sampling ψ angles of residue 172 from +0.3 to +3 radians. These transitions matched the behaviour of the β7-β8 hairpin known to drive switching.
4. Structure-only modelling without explicit physics
Using FoldToken to represent 3D structures as discrete tokens, the model predicts future conformations autoregressively. Despite no knowledge of bond lengths or energy functions, it generated diverse yet stable conformers aligned with experimental data.
I thought this was cool because it puts a complete spin on the usual MD logic. Instead of simulating motion step by step, it learns motion patterns and completes them like language. Almost musically.
That unlocks new possibilities. You can explore conformational states that standard MD would struggle to reach. You can train on a single state and find its alternative. And since it runs on standard AI hardware, it's fast and scalable.
MD-LLM-1 is still early. It doesn’t yet model thermodynamics or kinetics, and each protein needs separate fine-tuning. But it hints at something big: that language models might one day learn not just protein structure, but motion.
📄Check out the paper!
DINOv3-Brain: Mapping How Vision Models Learn Like Us
How Do Vision Transformers Learn to See Like Us?
We know deep vision models can sometimes mirror brain-like patterns but why that happens, and what drives it, hasn’t been completely clear.
This new study from Meta and ENS-PSL dissects that question by testing how model size, training length, and image type affect how closely a vision transformer (DINOv3) aligns with human brain activity. They compared internal model representations to fMRI and MEG responses from people viewing the same images.
The result is a clean, controlled look at how brain-model similarity actually forms. Very cool.
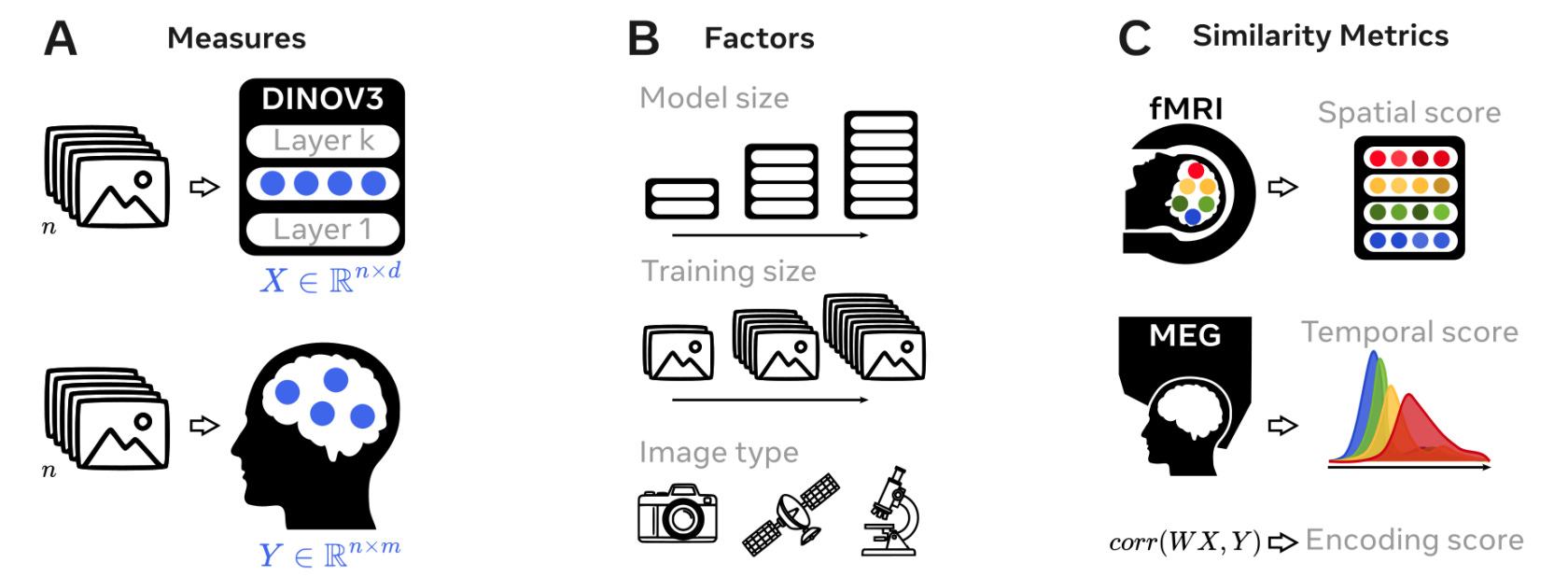
Applications and Insights
1. Brain alignment builds in stages
Early in training, DINOv3 matches low-level areas like V1. Later, alignment appears in prefrontal regions. Encoding scores peak at R = 0.45 in visual cortex and R = 0.09 in MEG signals from 70 ms onward.
2. Bigger models learn more brain-like features
DINOv3-Giant achieved R = 0.107 in high-level areas like BA44 and IFS. Smaller models aligned mostly with early visual regions.
3. What you train on really matters
Models trained on people-centric images showed stronger alignment across both sensory and prefrontal regions (p < 0.001), compared to those trained on satellite or cellular imagery.
4. Model convergence mirrors brain development
Alignment emerged first in fast, early regions and later in higher-order areas. Cortical expansion during development correlated strongly with model training dynamics (R = 0.88), suggesting shared organizational principles.
I thought this was cool because it shows that brain-like features in AI don’t just appear by chance. They actually emerge over time, shaped by scale, data, and training.
So, bottom line is this isn't just visual matching. It’s a parallel in how structure and meaning evolve, with fast sensory areas tuning in first and abstract ones catching up later, just like in humans.
In other words, we’re not just building models that act like brains. We might be uncovering how brains learn to become themselves. Really excited to see where this could take things.
📄Check out the paper!
⚙️Try it out the code.
FlowMol3: Fast Molecular Property Prediction at Scale
Most property prediction models available to us today trade off between accuracy, speed, and scalability. Transformer models give great performance but are expensive to train and hard to deploy. Equivariant graph neural networks (GNNs) respect molecular geometry but, on the other hand, scale poorly to large datasets. So, it’s pretty impossible to find a win-win.
FlowMol3 offers us a practical middle ground. It’s a simple but fast normalising flow architecture that learns a latent representation of 3D molecules and uses that to predict quantum properties and it does so without any message passing, attention, or equivariance layers.
Despite its simplicity, FlowMol3 matches or outperforms more complex models on several QM9 targets, and does so with 2 to 4× faster training and 10× faster inference.
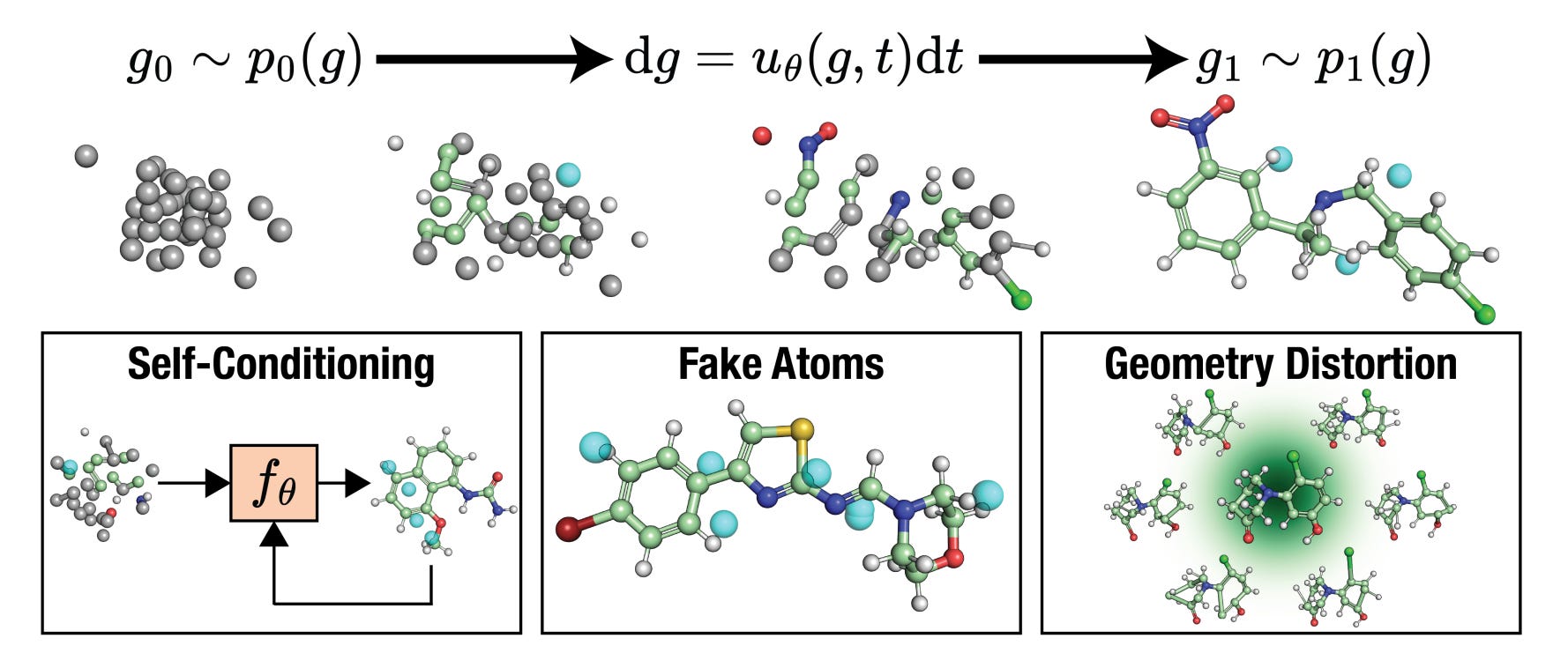
Applications and Insights
1. Latent geometry over heavy architectures
FlowMol3 uses a latent flow-based encoder (like GraphAF) and a coordinate decoder to reconstruct 3D structures. This captures molecular geometry without explicit MPNNs or symmetry constraints, keeping the model fast and lightweight.
2. Competitive accuracy on quantum benchmarks
On 6 out of 12 QM9 regression tasks, FlowMol3 matches or beats strong baselines like EGNN and SchNet, including on key properties like HOMO-LUMO gap and internal energy. On some tasks (e.g. U0), it improves performance by up to 19%.
3. Massively faster training and inference
FlowMol3 trains 2 to 4× faster than equivariant GNNs and runs 10× faster at inference. That makes it suitable for real-time pipelines or screening large molecule libraries where throughput matters.
4. Simple, clean, and scalable
No attention layers. No message passing. No force field pretraining. Just a compact latent flow with geometric reconstruction. This simplicity also makes it easier to adapt, fine-tune, or combine with other molecular representations.
I thought this was cool because it proves that you don’t always need deep symmetry or heavy transformers to do high-quality molecular modelling. Sometimes, just learning a clean latent space and decoding 3D structure is enough.
FlowMol3 won’t replace physics-informed models for everything but if you want fast, scalable property prediction that doesn’t overcomplicate things, I think it’s a pretty solid addition to the toolkit. As molecular modeling continues to scale to larger libraries and real-time applications, speed and simplicity are going to matter more than ever.
📄Check out the paper!
⚙️Try it out the code.
Thanks for reading!
Did you find this newsletter insightful? Share it with a colleague!
Subscribe Now to stay at the forefront of AI in Life Science.
Connect With Us
Have questions or suggestions? We'd love to hear from you!
📧 Email Us | 📲 Follow on LinkedIn | 🌐 Visit Our Website